Sustainable Systems: Operational Choices in Sustainable Architecture
In the second article in the Sustainable Systems series, Anne Currie focuses on operational choices you can make to improve how your software is run.

Anne Currie
Technologist and Author at Container Solutions

Introducing the SUSTAINABLE SYSTEMS article series
Sustainable Systems is a new articles series in the GSF blog. In her articles Anne Currie offers practical steps and guidance on sustainable systems and architecture.
The first in the series, Sustainable Tech Choices for Cloud, discussed why running highly available products and services on top of variably available power calls for flexibility and targeted efficiency not just from the cloud providers, but also their users.
As we discussed in the first part of this series , at the end of 2021, AWS added sustainability to the well-architected pillars that define their ”key concepts, design principles, and architectural best practices for designing and running workloads in the cloud.” A year earlier, Azure had posted their sustainable architecture guide, written by our own GSF chair, Asim Hussain.
Their cloud recommendations are covered in a new whitepaper on sustainable architecture for the cloud from the Coed:Ethics community in London, which the GSF is closely connected to.
What Does it Mean for Us?
In the last article, we outlined the four main approaches to tech sustainability:
- Operational efficiency (i.e. improving how software is run).
- Architecting for minimal carbon (improving how software is designed).
- Hardware efficiency (in particular, improving how end user devices are managed).
- Energy efficiency (minimization of CPU/GPU and network use).
In this post we will focus on the first: how to improve how your software is run.
What is Green Software?
Sustainable, aka green, software is designed and coded to require less power and fewer machines (aka carbon efficiency) to perform the same tasks. It also aims to draw power at times and in places where the available electricity comes from low carbon sources like wind, solar, geothermal, hydro, or nuclear. This is called carbon awareness and is a fundamental concept of sustainable computing.
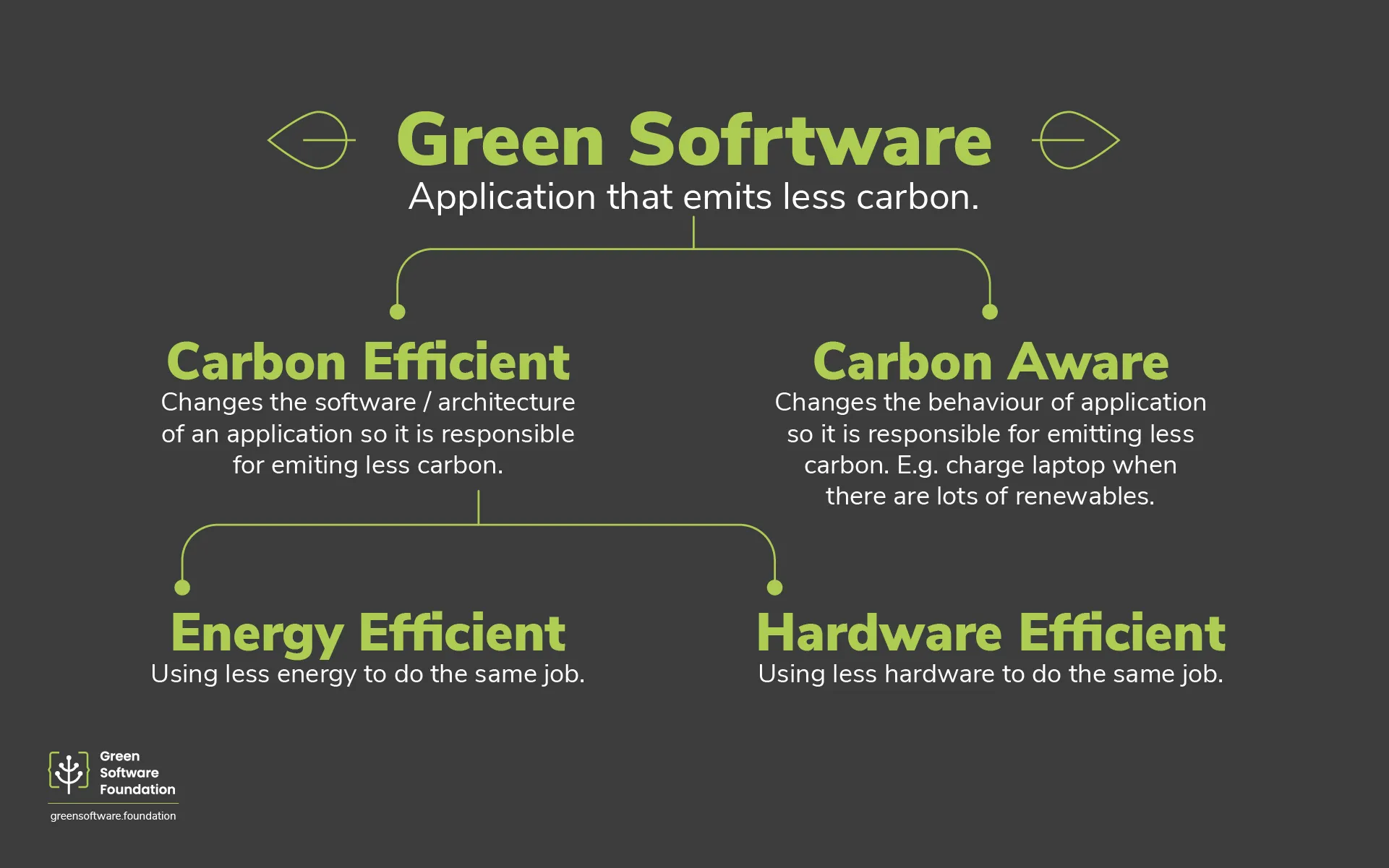 The Green Software Foundation’s definition of Green Software
The Green Software Foundation’s definition of Green Software
Operational Efficiency
It is possible to operate software applications in ways that are carbon aware, hardware efficient, and energy efficient. Unfortunately, that isn’t always the default. This concept of operational resource efficiency was pioneered by Google, although Azure and AWS are catching up.
Operational efficiency improvements are about achieving the same output with fewer machines and resources. This can potentially cut carbon emissions by five to tenfold. It is comparatively straightforward compared to other sustainability upgrades because services and tools already exist to support operational efficiency, particularly in the cloud.
High Server Density
The main way to reduce the emissions per unit of useful work is by running systems at very high utilization for processors, memory, disk space, and networking. This is often called operating at high server density. It improves both energy and hardware efficiency.
A good example of it can be seen in the work Google did last decade to improve their internal system utilization using cluster scheduling, as described in their Borg paper. More mundane examples, which can be applied both on prem and in the cloud, include not over provisioning systems—e.g. downsizing machines that are larger than necessary—or using autoscaling to avoid provisioning machines before they are required.
The hypercloud providers invest heavily in operational efficiency. As a result, the easiest sustainable step you can often take is to move systems to the public cloud. The machine utilization rates there usually significantly outstrip those achievable on premises (prem). Commonly this is over 65% versus between 10% to 20% average on prem. Note however, that if you just “lift and shift ” your existing servers on to dedicated virtual cloud ones, you won’t benefit from this high utilization rate.
The hyperclouds achieve this by packing workloads onto physical servers using their own smart orchestrators and schedulers if they can, that is if you haven’t hamstrung them by specifying dedicated servers. Note that even on prem rates can be significantly increased using a consumer cluster scheduler, for example Nomad from Hashicorp.
The cluster schedulers that optimize for machine utilization require encapsulated jobs —usually either in a VM, a container, or a serverless application—and they need to run on top of an orchestration layer that can start, stop or move those encapsulated jobs from machine to machine in order to maintain maximum packing.
It is vitally important that orchestrators and schedulers know enough to make smart placement decisions for jobs. If a scheduler knows more about the jobs it is scheduling, it can use resources more effectively. For example, on most clouds you can indicate the characteristics of a workload by picking the right instance type. You should not over-specify your resource or availability requirements, for example by asking for a dedicated instance when a burstable one would be enough.
Run Less
You should always close down applications and services that don’t do anything anymore. Holly Cummins of IBM Garage refers to them as “zombie workloads”. Don’t let them hang around “just in case”. If you can’t be bothered to automate starting and stopping them, that is a sign they aren’t valuable anymore. Unmaintained, zombie, workloads are bad for the environment as well as being a security risk. Shut them down.
Green Operational Tools and Techniques
Even if you run your work loads on the public cloud—i.e. operated by someone else—there are still operational efficiency configurations within your control.
- Spot instances on AWS or Azure, and preemptible instances on GCP are a key part of allowing the clouds to achieve their high utilization because they give orchestrators and schedulers discretion over when jobs are run. In the immediate term, using them everywhere that you can will make your systems more carbon efficient and cheaper. In the longer term, it will help your systems be more carbon aware, as Google implies in their recent paper on carbon aware data center operations.
- Overprovisioning reduces hardware and energy efficiency. Machines can be right sized using, for example, AWS Cost Explorer or Azure’s cost analysis. A simple audit can often identify those ‘zombie’ services which just need to be shut off.
- Autoscaling—having machines come online only when they are required—can be linked to CPU usage or network traffic levels or even configured predictively. Autoscaling minimizes the number of machines needed to run a system resiliently. AWS offers an excellent primer on microservice-driven auto-scalability. However, increasing architectural complexity by going overboard on the number of microservices can result in overprovisioning. There’s a balance here. Try to still keep it simple.
- Completely on demand or dedicated instance types have no carbon awareness. Choosing instance types that give the provider more flexibility will increase machine utilization and cut carbon emissions and costs. For example consider AWS T3 Instances or Azure B-series or Google shared-core machine types that offer bursting capabilities.
It is worth noting that architectures that recognize low priority and/or delayable tasks are easier to operate at high machine utilization. In the future, the same architectures will be better at carbon awareness. These include serverless, microservice, and other asynchronous (event-driven) architectures.
According to the green tech evangelist Paul Johnston, “Always on is unsustainable.” That may well be the death knell for many legacy monoliths.
Reporting Tools
Hosting cost is a reasonable proxy measure of carbon emissions and it is likely to become more closely correlated in the future as the cloud becomes increasingly commoditized, electricity remains a key underlying cost, and dirty electricity becomes more expensive through variable pricing. However, more targeted reporting tools do now exist. They are rudimentary, but better than nothing, and if they get used they’ll get improved. For example consider Google Carbon Footprint, Microsoft Emissions Impact Dashboard or the open source Cloud Carbon Footprint tool. An AWS one is coming in 2022.
In the next post in this series we’ll discuss architectural choices that can also help deliver greener software.
Have Comments or Questions?
Feel free to reach out on Twitter, LinkedIn, Medium or our Forum on Discourse when it is set up, and share your questions and comments.