Emission Calculations through Large Language Model
Five steps can help estimate software emissions during the system design phase using LLMs.
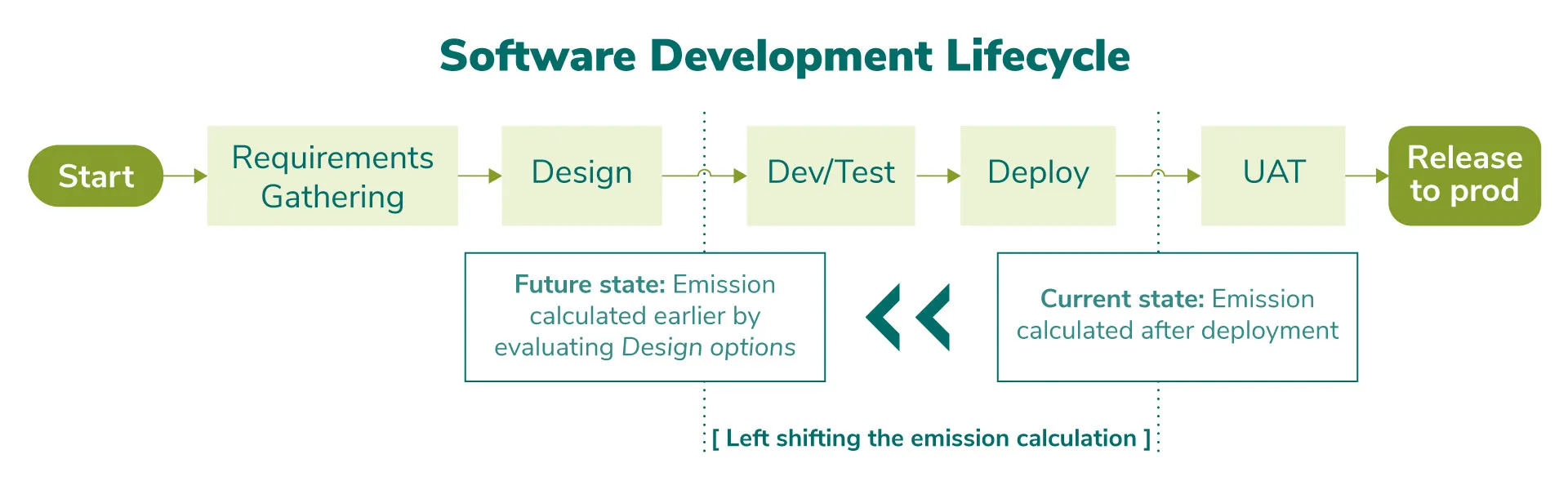
Emission calculations for software systems is an emerging area. In today’s world, emissions from software are typically calculated after it is deployed.
It’s also true that many design choices are made before software is built and deployed. These choices influence the overall carbon emission footprint. Yet today, no explicit guidance is available to evaluate the carbon impact of software design options, causing two problems:
- Opportunity Cost: The absence of tools to inform greener design choices leads to missed opportunities to avoid carbon emissions.
- Inflexibility: Once the system is operational, it is nearly impossible to revert to design and make changes with greener options.
Opportunity
If you search the public Internet, you can find good quality information on standard architecture and infrastructure configurations for software systems. Reference architectures are available for most types of applications: web applications, message broker apps, batch and cron jobs, long-running processes, SAP implementations, etc.
Additionally, information on green system designs and architectures is publicly available through the Green Software Foundation (GSF).
There is an opportunity to leverage all this information and estimate software emissions during the system design phase through a couple of measures:
- Mining and extracting useful information from the public domain of these artifacts and blueprints using the processing power available from AI and Large Language Models (LLMs).
- Training the models on vast amounts of design-related data to understand and generate text relevant to design concepts, specifications, and requirements.
- Training the models on energy and emission-efficient techniques to provide guidance to system designers and architects.
Background
System designers and architects design software systems. When they create software, they evaluate several technical design options and consider the pros and cons of each. These choices are made upstream in the software development lifecycle, long before lines of code are written, and can significantly affect the software’s carbon emissions during operation.
Consider these case study examples:
- E-commerce Site Architecture: Choosing an Active-Active setup for both primary and secondary regions without evaluating Green Design principles could lead to unnecessary carbon emissions.
- Web Application: Deciding whether to use an in-memory cache for frequently accessed data can significantly affect energy usage.
- Integration or Message Broker System: Choosing between publish-subscribe or store-forward messaging mechanisms depends on the specific context and functional/non-functional parameters like scalability, performance, and latency.
- Carbon-aware Workload Design: Ensuring the orchestrator of the workload is intelligent enough to choose the cloud region and the time of the day when the carbon intensity from the electricity grid is lower.
- AI Inference Optimization: Deciding how to deploy AI inference tasks can affect energy usage. For example, running AI inference tasks on specialized hardware such as GPUs or TPUs can be more energy-efficient than using general-purpose CPUs. Additionally, optimizing the models to run on edge devices closer to where data is generated can reduce the energy required for data transmission and processing in cloud data centers.
These examples highlight that design choices made during the requirements gathering/software design phases greatly impact carbon outcomes. These choices are made upstream in the software development lifecycle, much before lines of code are written. Hence, the opportunity lies in helping designers and architects in making greener design choices.
Solution Overview
The following steps can help estimate software emissions during the system design phase using LLMs:
- Data Collection and Preparation:
- Architecture and Design Documents: Collect publicly available architecture diagrams, technical design documents, and system specifications. These documents provide insights into design choices and their implications.
- Requirements Documents: Gather requirements documents that capture functional and non-functional requirements, as these influence design decisions.
- Green Design Patterns: Collect information on green design principles and practices from the GSF and other relevant literature sources.
- Training the LLM:
- Dataset Creation: Create a comprehensive dataset of the collected documents. Annotate the dataset to highlight design choices, carbon impact considerations, and green practices.
- Model Training: Use the annotated dataset to train an LLM. The model should be capable of understanding design concepts, specifications, and requirements. Fine-tune the model to recognize and suggest energy-efficient and carbon-aware design options.
- Implementing Retrieval-Augmented Generation (RAG):
- Knowledge Base Creation: Develop a knowledge base containing best practices, design patterns, and green software principles. A knowledge base of this kind will serve as the foundation for the retrieval-augmented generation process.
- Integration with LLM: Integrate the LLM with the knowledge base. Use the LLM to generate design suggestions and evaluate existing design choices based on the information retrieved from the knowledge base.
- Developing the Solution Architecture:
- Data Ingestion Module: Build a module to ingest new design documents, requirements, and specifications. This module should preprocess the data and prepare it for analysis.
- LLM Inference Engine: Develop an inference engine that leverages the trained LLM to analyze the ingested data. The engine should identify design choices and assess their carbon impact.
- Recommendation System: Implement a recommendation system that provides design suggestions to system designers and architects, highlighting greener alternatives and quantifying potential carbon savings.
- User Interface: Design a user-friendly interface for system designers and architects to interact with the tool. The interface should allow users to input design documents and receive actionable insights.
- Validation and Continuous Improvement:
- Validation Framework: Establish a validation framework to assess the accuracy and effectiveness of the LLM-generated recommendations. Refine the model using real-world case studies and feedback from domain experts.
- Continuous Learning: Implement a continuous learning mechanism to update the model with new data and evolving green design practices. Regularly retrain the model to ensure it remains relevant and accurate.
Below is a reference architecture overview of how the above building blocks can work to build an LLM platform. The architecture is meant to be logical.
By following these steps, the solution can effectively estimate software emissions during the design phase and provide actionable insights to system designers and architects, enabling them to make greener design choices and reduce software systems’ carbon footprint.
For more information, connect with Navveen Balani or Srinivasan Rakhunathan on LinkedIn or GSF Discussions @navveenb and @srini1978.
About the Authors
Srinivasan Rakhunathan
Srini is a Technical Product Manager with Microsoft. He has a software engineering background and has performed various roles including Developer, Architect, Program Manager etc. He has been involved with the GSF since 2021 and has contributed to projects like SCI specifications, Impact Framework, Green software practices.
Srini is also a regular speaker at GSF and Microsoft conferences. His interests are sustainable software engineering, architecture and product management.
Navveen Balani
Navveen Balani is the Managing Director and Chief Technologist of Technology Sustainability Innovation at Accenture. In this role, he leads various research and innovation initiatives focused on technology sustainability. Navveen serves as the co-chair for the Standards Working Group and the Impact Framework at the GSF. He has been actively involved with the GSF since its inception. Navveen is also the author of several leading technology books.